Training and evaluating a text classifier
Develops and measures the effectiveness of a model that automatically categorizes text data. Ensures systematic evaluation for reliable real-world deployment.
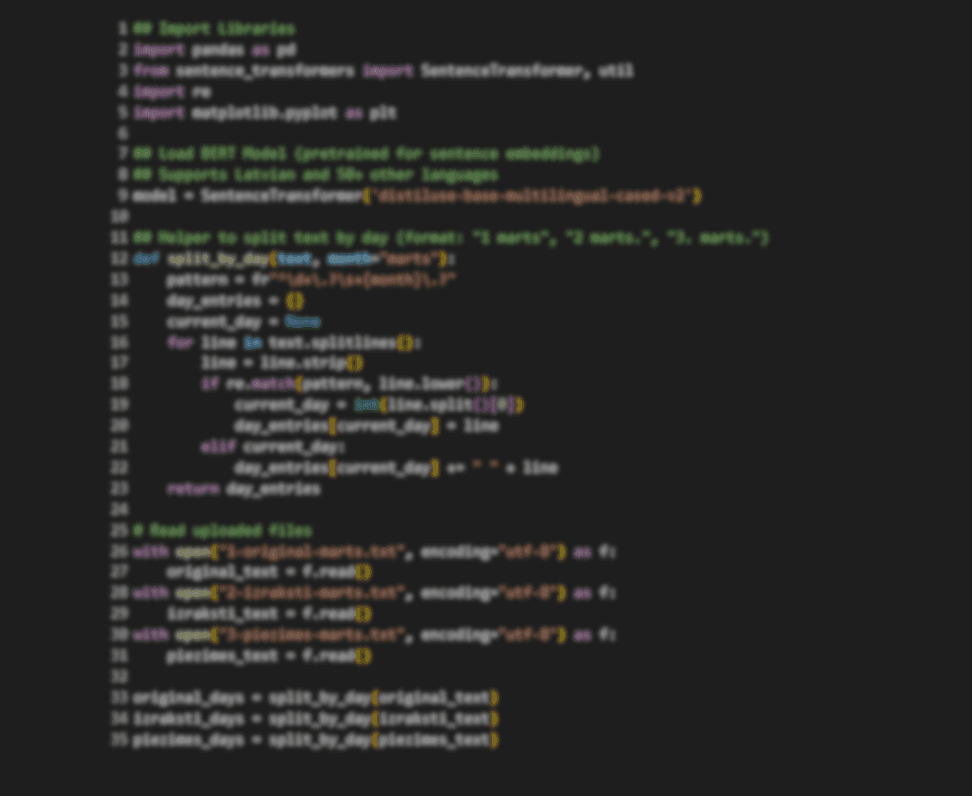
About the Project
This project focuses on the full pipeline of building, training, and evaluating a machine learning text classifier. It covers dataset preparation, feature extraction (such as bag-of-words or embeddings), model selection, and training procedures. The project includes rigorous evaluation using metrics like accuracy, precision, recall, and F1-score to assess the model’s performance.
Client
Private
Industry
TECH
Category
Web Developent
Duration
1 month
The project for training and evaluating a text classifier addresses the core challenges in automating text categorization tasks, such as sentiment analysis, spam detection, or topic assignment. The process starts with thorough data preparation, including cleaning, tokenization, and transforming raw text into machine-readable features. Multiple algorithms—ranging from Naive Bayes and logistic regression to more advanced neural networks—can be trained on the processed data, allowing for flexible adaptation to project requirements and available computational resources.
Evaluation is systematic and rigorous, using industry-standard metrics like accuracy, precision, recall, and F1-score to objectively assess performance. The workflow also includes techniques for model validation, such as cross-validation and the use of test datasets, to prevent overfitting and measure real-world effectiveness. Modular code structure and integration with established machine learning libraries (like scikit-learn or TensorFlow) make this project easy to extend or adapt for specific use cases. The end goal is to deliver a robust, reproducible process for building text classifiers that perform reliably in practical applications.

