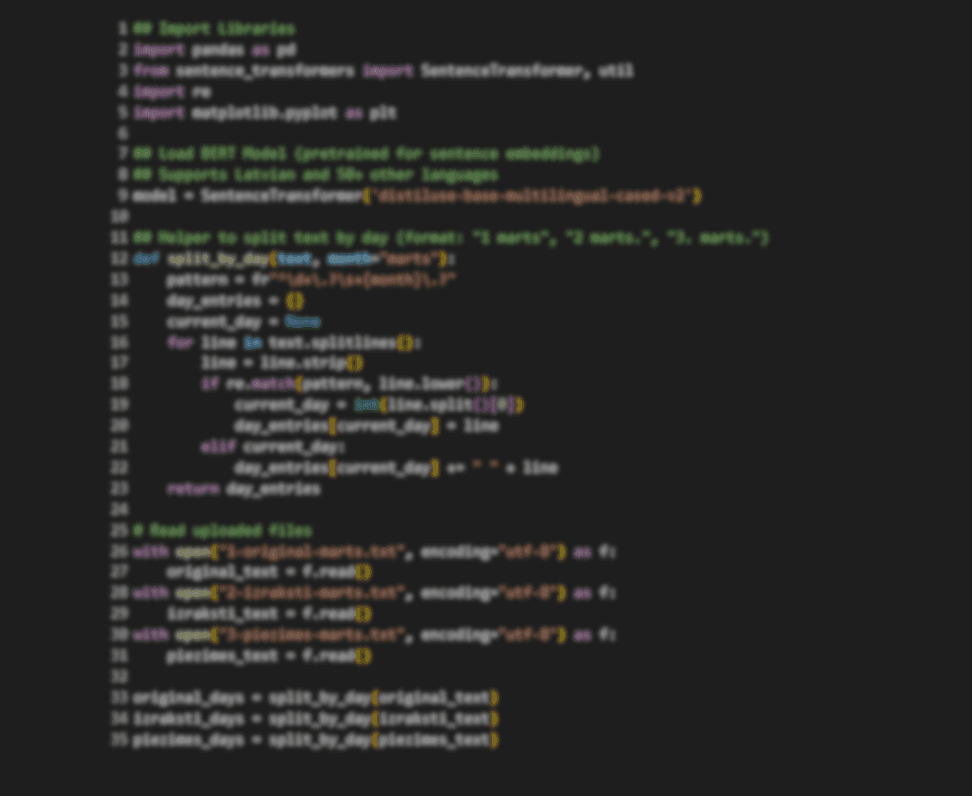
ID sorting algorithm for a database
Efficiently organizes database records by their unique identifiers. Ensures fast retrieval and streamlined data management for systems relying on ID-based access.

About the Project
This project implements a high-performance sorting algorithm tailored for organizing records in a database by their unique IDs. The solution addresses both numeric and alphanumeric ID schemes, optimizing sort operations for large-scale datasets. Key goals include minimizing computational overhead, reducing memory usage, and integrating smoothly with existing database management systems.
Client
Private
Industry
TECH
Category
SAAS
Duration
3 months
The ID Sorting Algorithm for a database is designed to address the growing need for rapid and reliable data organization in environments where each record is uniquely identified. By focusing on the primary key (ID), the algorithm ensures that all records can be accessed, retrieved, and updated with maximum efficiency. It supports both integer and alphanumeric ID formats, making it suitable for a wide range of databases, from transactional systems to document archives. The implementation prioritizes speed and resource efficiency, minimizing CPU and memory consumption even when handling millions of entries.
Beyond simple sorting, the algorithm is robust enough to manage edge cases such as duplicate IDs and missing values. Its stable sort behavior guarantees that the relative order of records with equivalent IDs remains unchanged, which is critical in multi-field sorting or audit scenarios. Designed for seamless integration, it can be adapted to SQL-based or NoSQL database systems and is easily extendable for custom sorting rules or additional indexing requirements. This project provides both command-line and API access for maximum usability in automation workflows or larger data processing pipelines.